DDPG の実装
Contents
7. DDPG の実装#
本章では DDPG の実装を扱っていきます.
本章ではPendulum環境に DDPG を適用していきます. この環境は入力が 1 次元(振り子の軸についているモーターのトルク)で,出力が 3 次元(振り子の xy 座標 + 角速度)となっています. 報酬設計は
となっており,上で静止するほど報酬が大きくなる(0に近くなる)ようになっています.
import gnwrapper
import gym
env = gnwrapper.LoopAnimation(gym.make("Pendulum-v1"))
env.reset()
while True:
next_state, reward, done, info = env.step(env.action_space.sample()) # ランダムに行動
env.render() # 描画
if done:
break
env.display()
state_size = env.observation_space.shape[0] # 状態の次元
action_size = env.action_space.shape[0] # 行動の次元
GAMMA = 0.99 # 割引率
env = env.env
/home/hisaki/workspace/rl-semi/.venv/lib/python3.8/site-packages/gym/utils/passive_env_checker.py:97: UserWarning: WARN: We recommend you to use a symmetric and normalized Box action space (range=[-1, 1]) https://stable-baselines3.readthedocs.io/en/master/guide/rl_tips.html
logger.warn(

まずは,必要なモジュールを import や乱数シードの固定,デバイスの指定を行います.
from copy import deepcopy
import numpy as np
import torch
from torch import nn
import torch.nn.functional as F
from torch.optim import Adam
import random
# fix seed
torch.manual_seed(0)
random.seed(0)
np.random.seed(0)
env.action_space.seed(0)
env.reset(seed=0)
# デバイスを指定
# CUDAが使えるなら"cuda"に,無理なら"cpu"に
DEVICE = "cuda"
# DEVICE = "cpu"
7.1. Replay Buffer の実装#
まずは,Replay Buffer クラスを実装します.
このクラスはappend関数で経験を保存し,sampleで全経験からミニバッチを一様ランダムにサンプルします.
class ReplayBuffer(object):
def __init__(self) -> None:
self.memory = []
def append(self, state, action, next_state, reward, done):
"""経験を保存する"""
self.memory.append((state, action, next_state, reward, done))
def sample(self, batch_size):
"""ミニバッチをサンプルする"""
# ランダムに経験をサンプル
sampled = random.sample(self.memory, batch_size)
# ミニバッチを使いやすいようにdict形式のコンテナに入れる
batch = dict(state=[], action=[], next_state=[], reward=[], done=[])
for state, action, next_state, reward, done in sampled:
batch["state"].append(state)
batch["action"].append(action)
batch["next_state"].append(next_state)
batch["reward"].append(reward)
batch["done"].append(done)
# torch.Tensor型で経験を使うことが多いため,キャストを行う
for key in batch.keys():
batch[key] = torch.tensor(np.array(batch[key]), dtype=torch.float32, device=DEVICE)
return batch
rb = ReplayBuffer() # インスタンスを生成
7.2. Actor/Critic の実装#
実装上では,方策をActorという名前で実装し,
方策を評価する行動価値関数をCriticという名前で実装します.
本節では
各ネットワーククラスを定義
インスタンスを生成
最適化器のインスタンスの生成
を行います.
7.2.1. Actor#
class Actor(nn.Module):
def __init__(self, state_size, action_size) -> None:
super().__init__()
self.linear0 = nn.Linear(state_size, 400)
self.relu0 = nn.ReLU()
self.linear1 = nn.Linear(400, 300)
self.relu1 = nn.ReLU()
self.linear2 = nn.Linear(300, action_size)
self.tanh2 = nn.Tanh()
def forward(self, state):
"""a = mu(s)"""
h0 = self.relu0(self.linear0(state))
h1 = self.relu1(self.linear1(h0))
action = (
self.tanh2(self.linear2(h1)) * 2.0
) # tanh(x)は[-1,1]の範囲だが,Pendulmの行動は[-2,2]となるため.
return action
actor = Actor(state_size=state_size, action_size=action_size).to(DEVICE) # actorのインスタンスを生成
actor_optimizer = Adam(actor.parameters(), 1e-3) # 最適化のインスタンスを生成
actor_targ = deepcopy(actor).to(DEVICE).requires_grad_(
False
) # ターゲットネットワークの生成(勾配は計算しないのでrequires_grad_をFalseにする)
print(actor)
Actor(
(linear0): Linear(in_features=3, out_features=400, bias=True)
(relu0): ReLU()
(linear1): Linear(in_features=400, out_features=300, bias=True)
(relu1): ReLU()
(linear2): Linear(in_features=300, out_features=1, bias=True)
(tanh2): Tanh()
)
7.2.2. Critic#
class Critic(nn.Module):
def __init__(self, state_size, action_size) -> None:
super().__init__()
self.linear0 = nn.Linear(state_size + action_size, 400)
self.relu0 = nn.ReLU()
self.linear1 = nn.Linear(400, 300)
self.relu1 = nn.ReLU()
self.linear2 = nn.Linear(300, action_size)
def forward(self, state, action):
"""Q(s,a)"""
sa = torch.cat([state, action], dim=1) # 状態と行動の次元を結合
h0 = self.relu0(self.linear0(sa))
h1 = self.relu1(self.linear1(h0))
y = self.linear2(h1)
return y
critic = Critic(state_size=state_size, action_size=action_size).to(
DEVICE
) # criticのインスタンスを生成
critic_optimzer = Adam(critic.parameters(), 1e-3) # 最適化のインスタンスを生成
critic_targ = (
deepcopy(critic).to(DEVICE).requires_grad_(False)
) # ターゲットネットワークの生成(勾配は計算しないのでrequires_grad_をFalseにする)
print(critic)
Critic(
(linear0): Linear(in_features=4, out_features=400, bias=True)
(relu0): ReLU()
(linear1): Linear(in_features=400, out_features=300, bias=True)
(relu1): ReLU()
(linear2): Linear(in_features=300, out_features=1, bias=True)
)
7.3. 損失関数の計算#
7.3.1. 行動価値関数の損失の計算#
ミニバッチを引数にとり,返り値として行動価値関数の損失を返す関数を作成します. Algorithm 5.1より,行動価値関数の損失は以下の式で計算されます.
ただし,シミュレーション環境には終了状態が存在するため,Q-learningの実装と同様の処理を考えます.
終了フラグ\(\text{done}\)(\(s'\)が終了状態だとTrue)に対しターゲットは以下のようになります.
実装は以下のようになります.
def compute_loss_q(batch):
"""行動価値関数の損失を計算"""
state, action, next_state, reward, done = (
batch["state"],
batch["action"],
batch["next_state"],
batch["reward"],
batch["done"],
) # ミニバッチのデータを取り出す
q_pred = critic(state, action).squeeze() # q(s,a)を計算する
with torch.no_grad(): # ターゲットの計算には勾配が不要
next_action = actor_targ(next_state) # a' = mu_targ(s')を計算
y = (
reward + GAMMA * (1 - done) * critic_targ(next_state, next_action).squeeze()
) # ターゲットを計算
loss = F.mse_loss(q_pred, y) # 損失を計算
return loss
7.3.2. 方策の損失を計算#
ミニバッチを引数にとり,返り値として方策の損失を返す関数を作成します. Algorithm 5.1より,方策の損失は以下の式で計算されます.
実装は以下のようになります.
def compute_loss_policy(batch):
"""方策の損失を計算"""
state = batch["state"]
action = actor(state)
loss: torch.Tensor = -critic(state, action) # q(s,mu(s))の最大化を-q(s,mu(s))の最小化と捉える
return loss.mean()
7.4. 行動方策の定義#
次に,行動方策を表す関数を定義します. 行動方策は,ここの説明より,現在の方策が最良とする行動にガウシアンノイズを加えたものです. 実際の行動には範囲が有るため,上下限でクリッピングを行います.
以下,現在の状態と加えるノイズの偏差を引数にとり,行動方策より行動を選択する関数を実装します.
def behavior_policy(state, noise_scale):
"""行動方策"""
with torch.no_grad(): # 勾配計算の必要は無い
action = actor(torch.tensor(state, device=DEVICE)).cpu().detach().numpy()
action += noise_scale * np.random.randn(action_size) # ノイズを加える
action = np.clip(action, env.action_space.low, env.action_space.high) # 行動を上下限内に収める
return action
7.5. ターゲットネットワークの更新#
DDPG のターゲットネットワークの節で解説したターゲットネットワークの更新を実装します.
方策,行動価値関数のターゲットネットワークは以下の式のように更新されます.
引数として,元のネットワークとターゲットネットワークとパラメータ\(\rho\)を受け取り, ターゲットネットワークを更新する関数を定義します.
def delay_update(src: nn.Module, targ: nn.Module, rho: float):
"""ターゲットネットワークを遅れて更新"""
for p, p_targ in zip(src.parameters(), targ.parameters()):
p_targ.data.mul_(rho)
p_targ.data.add_((1 - rho) * p.data)
7.6. 学習#
ここまで用意したものを用いて,Algorithm 5.1に従い学習ループを実装します. 細かい説明はコードのコメント内に記載します. 以下が実装となります.
def evaluate(env: gym.Env, actor: Actor):
"""
実際にActorを用いて行動し,10エピソードでの報酬和の平均を得る.
この関数を用いてActor(方策)の評価を行う.
"""
rewards = []
for i in range(10):
state = env.reset()
reward_sum = 0.0
while True:
action = actor(torch.tensor(state, device=DEVICE)).cpu().detach().numpy()
next_state, reward, done, _ = env.step(action)
reward_sum += reward
if done:
rewards.append(reward_sum)
break
else:
state = next_state
return np.mean(rewards)
train_step = 30000 # 全トレーニングステップ数
start_step = 5000 # start_stepまでは完全にランダムに行動する
start_update_step = 1000 # パラメータの更新を開始するステップ数
batch_size = 256 # バッチサイズ
rho = 0.995 # ターゲットネットワークの更新のパラメータ
noise_scale = 0.2 # 行動方策のノイズの偏差
eval_interval = 1000 # eval_intervalステップおきに方策を評価する
eval_log = [] # 評価値のログ
state = env.reset()
for step in range(train_step): # 学習ループをtrain_step回まわす
if step < start_step:
action = env.action_space.sample() # 学習初期は完全にランダムに行動する.
else:
action = behavior_policy(state, noise_scale) # 行動方策で行動を選択
next_state, reward, done, _ = env.step(action) # 行動を実行
rb.append( # 経験を蓄積
state=state,
action=action,
next_state=next_state,
reward=reward,
done=False
if env._elapsed_steps == env._max_episode_steps
else done, # ステップが終了ステップに達していたら,次状態は終了していない
)
if step > start_update_step: # 10000ステップ以降から更新を開始
batch = rb.sample(batch_size=batch_size) # ミニバッチをサンプル
q_loss = compute_loss_q(batch) # qの損失を計算
critic_optimzer.zero_grad() # パラメータの勾配を初期化
q_loss.backward() # 損失から勾配を計算
critic_optimzer.step() # 1ステップパラメータを更新する
actor_optimizer.zero_grad() # muの損失を計算
policy_loss = compute_loss_policy(batch) # パラメータの勾配を初期化
policy_loss.backward() # 損失から勾配を計算
actor_optimizer.step() # 1ステップパラメータを更新する
with torch.no_grad(): # ターゲットネットワークを更新
delay_update(critic, critic_targ, rho)
delay_update(actor, actor_targ, rho)
if step % eval_interval == 0: # eval_intervalステップおきに評価値を計算
score = evaluate(env, actor)
print(f"step : {step}, score : {score}")
eval_log.append(score)
if done:
state = env.reset()
else:
state = next_state
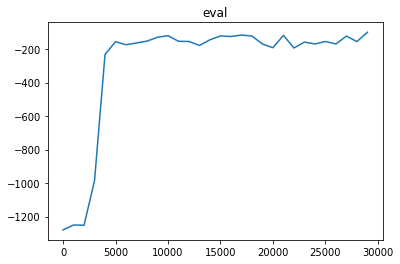
step : 0, score : -1279.3398877621853
step : 1000, score : -1249.9616297846217
step : 2000, score : -1251.4804840786921
step : 3000, score : -985.2630807387466
step : 4000, score : -232.29490487791622
step : 5000, score : -156.14637774295142
step : 6000, score : -174.50819113853925
step : 7000, score : -163.8454046563415
step : 8000, score : -152.9289411376712
step : 9000, score : -129.92836057983646
step : 10000, score : -120.25784217763176
step : 11000, score : -153.92856795443893
step : 12000, score : -155.0368226154883
step : 13000, score : -178.70993641442163
step : 14000, score : -144.73706564102062
step : 15000, score : -121.9776650976074
step : 16000, score : -125.2812951791619
step : 17000, score : -116.64928148642628
step : 18000, score : -122.32523981223065
step : 19000, score : -170.2570059878385
step : 20000, score : -192.14161401070763
step : 21000, score : -118.53005378190275
step : 22000, score : -193.80636506001514
step : 23000, score : -158.62034334371953
step : 24000, score : -169.83166719008665
step : 25000, score : -155.07903900114042
step : 26000, score : -169.8910468688394
step : 27000, score : -122.87518702895186
step : 28000, score : -155.56624641917125
step : 29000, score : -99.91184918109
ここで,注意点が3点あります.
本実装において,探索をより重視するため,学習初期(学習ステップが
start_stepに到達するまで)は,完全にランダムに行動しています.パラメータの更新を開始するのは,十分に経験を収集してから(学習ステップが
start_update_stepに到達してから)です.シミュレーションは,エピソードの経過ステップ
env._elapsed_stepsがenv._max_episode_stepsに達したらdoneがTrueになり打ち切られてしまいます.しかし,この場合はnext_stateが終了状態に達したわけではないので,蓄積する経験ではdoneをFalseにします.
7.7. 実行結果#
実行結果をビジュアライズすると,以下のようになります.
評価値の推移
import matplotlib.pyplot as plt
plt.plot([i * eval_interval for i in range(train_step // eval_interval)], eval_log)
plt.title("eval")
plt.show()
得られた方策で行動した結果
env = gnwrapper.LoopAnimation(env)
state = env.reset()
while True:
action = actor(torch.tensor(state, device=DEVICE)).cpu().detach().numpy()
next_state, reward, done, info = env.step(action) # ランダムに行動
env.render() # 描画
if done:
break
else:
state = next_state
env.display()
