ベルマン方程式
Contents
3. ベルマン方程式#
本章では,価値関数/行動価値関数が満たす再帰的な性質を基にした ベルマン方程式(Bellman equation) を紹介します. この方程式は,現在の状態\(s\)の価値\(V(s)\)と次の状態\(s'\)の価値\(V(s')\)の関係に着目することにより得られる方程式で, 様々な強化学習アルゴリズムで利用されています.
3.1. ベルマン方程式#
価値関数の定義式(2.1)と\(G_t\)に関する再帰的な式(2.4)より以下のような式変形が行えます.
この式変形は直感的に,「現在の状態の価値 = (即時報酬 + 次の状態の価値)の期待値」としたものであると捉えることが出来ます.
同様の式変形を行動価値関数に関しても適用できます.
これらの式変形より,\(V^\pi\)は関数\(v : \mathcal{S} \rightarrow \mathbb{R}\)に関する方程式
の解であることがわかり, \(Q^\pi\)は関数\(q : \mathcal{S} \times \mathcal{A} \rightarrow \mathbb{R}\)に関する方程式
の解であることがわかります. 方程式(3.3),(3.4)はベルマン方程式と呼ばれています.
これらの方程式の嬉しいところは, 環境が既知であるならば, \(V^\pi,Q^\pi\)を求める問題を方程式(3.3),(3.4)の解を求める問題と捉えることが出来ることです.
が成り立つ,つまり,\(V^\pi\)が求まれば\(Q^\pi\)も求まるため本節では主に価値関数についてのみ扱います.
3.1.1. ベルマン作用素#
ベルマン方程式をより深く分析するため,ベルマン方程式を基にした ベルマン作用素(Bellman operator) というものを導入します.
ベルマン作用素は,ある関数\(v : \mathcal{S} \rightarrow \mathbb{R}\)に対する写像\(B_\pi: \mathbb{R}^{|\mathcal{S}|} \rightarrow \mathbb{R}^{|\mathcal{S}|}\)であり,
と定義されます.
このベルマン作用素を用いて,式(3.3)のベルマン方程式を以下のように書き表せます.
このように,ある作用素に対して\(v = B(v)\)のような関係を成り立たせる\(v\)を不動点(fixed-point) と呼びます.
また,この作用素は同じ関数に k 回適用した場合,つまり\(B( \cdots B(B(v)))\)とした場合\(B^k(v)\)のように表記します.
このベルマン作用素に対して以下の命題が成り立ちます.
Proposition 3.1
ベルマン作用素\(B_\pi\)は,
を満たす唯一の不動点\(v^*\)を持つ. また,任意の有界関数\(v_0:\mathcal{S} \rightarrow \mathbb{R}\) に対して$B_\piを繰り返し適用すると漸近的に不動点に等しくなる.
Proof. \(B_\pi\)が最大ノルムに対して縮小写像であることを示すことを示すことにより, バナッハの不動点定理より, ベルマン作用素が唯一の不動点を持ち, 任意の\(v\)にベルマン作用素を繰り返し適用することで,不動点に漸近的に等しくなることがわかります. 詳しくは追記します.
\(V^\pi\)はベルマン作用素の不動点の一つであること,ベルマン作用素は不動点を一つしか持たないことより,\(V^\pi\)はベルマン作用素の唯一の不動点(ベルマン方程式の唯一解)であると言えます.
これらの命題より,環境の情報が既知である場合
\(v = B_\pi(v), \forall s \in \mathcal{S}\)を直接解く
任意の関数\(v\)に対して\(B_\pi\)を繰り返し適用する
の2通り方法で\(V^\pi\)を得ることが出来ます.
3.1.2. 実装#
本節では,前節のコンセプトを基にした手法の実装を示し, 実際にFrozenLake環境に適用してみます.
import gym
env = gym.make(
"FrozenLake-v1",
desc=["SFFF", "FHFH", "FFFH", "HFFG"],
map_name="4x4",
)
%matplotlib inline
import matplotlib.pyplot as plt
env.reset()
plt.imshow(env.render(mode='rgb_array'))
<matplotlib.image.AxesImage at 0x7f6550175250>

まずは,実装上扱いやすくするために,ベルマン方程式(3.3)を,行列形式(テーブル型)に変換してみます. 状態空間\(\mathcal{S}\)は有限であるため, 関数\(v : \mathcal{S} \rightarrow \mathbb{R}\)は,以下のようなベクトル\(v \in \mathbb{R}^{|\mathcal{S}|}\)と等価であるとみなすことが出来ます.
価値関数以外にも,環境の情報も行列形式にすることが可能です.報酬の期待値\(g(s) = \sum_{a \in \mathcal{A}} \pi(a|s) r(s,a)\)も価値関数と同様にベクトル\(g \in \mathbb{R}^{|\mathcal{S}|}\)とします.
方策\(\pi\)上で状態\(s\)から\(s'\)に遷移する確率\(P_\pi(s,s') = \sum_{a \in \mathcal{A}} \pi(a|s) p(s'|s,a)\)を確率行列 \(P_\pi \in \mathbb{R}^{|\mathcal{S}| \times |\mathcal{S}|}\)とします.
これらの行列を用いてベルマン方程式(3.3)を書き表すと,
となり,一般的な行列計算として実装上でも扱いやすい形となります.
FrozenLake環境において,行動を一様ランダムに選択,つまり\(\pi(a|s) = \frac{1}{4}\)とした場合の環境情報\(g, P_\pi\)を求めると以下のようになります.
import numpy as np
np.set_printoptions(threshold=16)
state_size = env.observation_space.n
action_size = env.action_space.n
# FrozenLakeの内部実装を参考に,状態遷移関数を作成する
def p(sp, s, a):
"""状態遷移関数
Args:
sp : 次の状態 s'
s : 現在の状態 s
a : 現在の状態で選択する行動 a
Returns:
sでaを選択した後s'に遷移する確率
"""
transition = env.P[s][a]
prob = 0.0
for t in transition:
if t[1] == sp:
prob += t[0]
return prob
# FrozenLakeの内部実装を参考に,報酬関数を作成する
def r(s, a):
"""報酬関数
Args:
s : 現在の状態 s
a : 現在の状態で選択する行動 a
Returns:
報酬r(s,a)
"""
transition = env.P[s][a]
reward = 0.0
for t in transition:
reward += t[0] * t[2]
return reward
def pi(a, s):
"""方策"""
return 1.0 / 4.0
P = np.zeros((state_size, state_size))
for s in range(state_size):
for sp in range(state_size):
P[s, sp] = np.sum([pi(a, s) * p(sp, s, a) for a in range(action_size)])
g = np.zeros((state_size,))
for s in range(state_size):
g[s] = np.sum([pi(a, s) * r(s, a) for a in range(action_size)])
P =
[[0.5 0.25 0. ... 0. 0. 0. ]
[0.25 0.25 0.25 ... 0. 0. 0. ]
[0. 0.25 0.25 ... 0. 0. 0. ]
...
[0. 0. 0. ... 0.25 0.25 0. ]
[0. 0. 0. ... 0.25 0.25 0.25]
[0. 0. 0. ... 0. 0. 1. ]]
g =
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0.25 0. ]
これらをもとに前述の 2 つの手法を用いて,価値関数を求めていきます.
まずは,ベルマン方程式を直接解く手法により,価値関数を求めます. 式(3.6)の方程式の解は
となるため,この式を用いて解を求めます.
GAMMA = 0.99 # 割引率
v1 = np.linalg.inv(np.eye(state_size, state_size) - GAMMA * P) @ g
print(f"v1 =\n{v1}")
v1 =
[ 1.23561373e-02 1.04244610e-02 1.93384359e-02 9.47774828e-03
1.47870516e-02 -2.05729297e-16 3.88944494e-02 -8.26986330e-16
3.26024740e-02 8.43376421e-02 1.37810854e-01 0.00000000e+00
-2.05408145e-16 1.70344822e-01 4.33579442e-01 0.00000000e+00]
次に,ベルマン作用素を繰り返し適用する手法を実装します.
任意の関数v2(ここではゼロで初期化)に\(B_\pi\)を繰り返し適用し,価値関数を求めると以下のようになります.
v2 = np.zeros((state_size,)) # 価値関数の初期値
v2_log = [v2] # ログ保存用のリスト
for _ in range(50):
v2 = g + GAMMA * P @ v2 # ベルマン作用素により更新
v2_log.append(v2) # ログを保存
print(f"v2 =\n{v2}")
v2 =
[0.01235348 0.01042258 0.01933677 0.00947646 0.01478549 0.
0.0388938 0. 0.03260156 0.08433709 0.13781037 0.
0. 0.17034441 0.43357905 0. ]
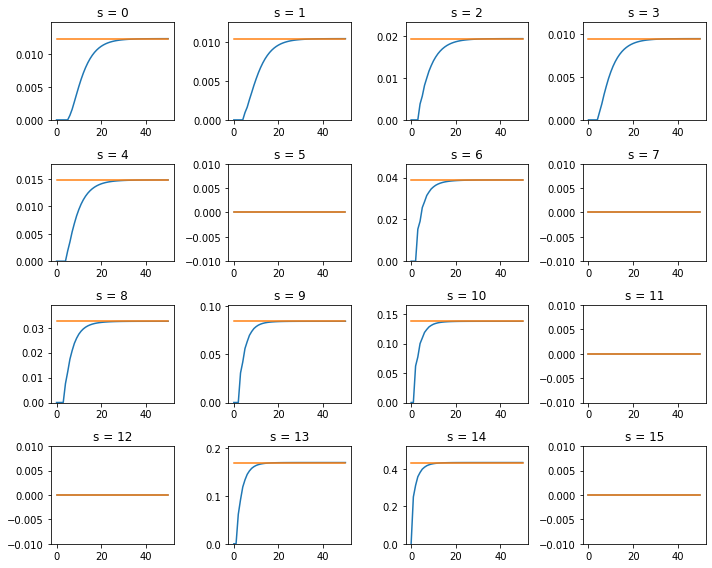
2 つの手法で求めた解を比べると以下のようになります.
v2_log = np.array(v2_log)
plt.figure(figsize=(10, 8))
for i in range(state_size):
plt.subplot(4, 4, i + 1)
plt.plot(v2_log[:, i])
plt.plot([v1[i] for _ in v2_log[:, i]])
if abs(v1[i]) < 1e-5:
plt.ylim(-0.01, 0.01)
else:
plt.ylim(0.0, v1[i] * 1.2)
plt.title(f"s = {i}")
plt.tight_layout()
3.2. ベルマン最適方程式#
これまでは,任意の方策に対する価値関数/ベルマン方程式を見てきました. 本章では,これまで紹介してきたものを用いて 最適方策 を導入していきます.
3.2.1. 最適方策#
最適方策は以下のように定義されます.
Definition 3.1
任意の初期状態\(s \in \mathcal{S}\)からの期待リターンを最大化する方策\(\pi^*\)を最適方策と呼ぶ. 最適方策\(\pi^*\)の価値関数\(V^{\pi^*}(s) = V^*(s)\)は任意の方策\(\pi\)に対して以下が成り立つ
また,最適方策の価値関数 \(V^{\pi^*}(s) = V^*(s)\) を最適価値関数と呼びます. この最適方策の定義は,全ての初期状態からの期待リターンを最大化するものであり, 単一の初期分布からの期待リターンを評価関数とし,それを最大化するだけではないのです. しかし,このような条件を満たす最適方策は本当に存在するのでしょうか? 結論から言うと,最適方策は存在し(これは複数存在する可能性あり),それらは一意の最適価値関数を持ちます.
以下それを説明していきます.
3.2.2. ベルマン最適方程式#
Proposition 3.2 (方策の改善)
任意の方策\(\pi\)に対して,
とした場合,
となる.
Proof. 任意の\(s\in\mathcal{S}\)に対して
が成り立つため,Proposition 3.2は成立する.
Proposition 3.2より,\(\pi\)を\(\pi'(a|s) = \delta_{a,\mu(s)}\)と更新した際,\(\pi'\)は\(\pi\)より良くなることがわかります. また,状態空間/行動空間が有限であるため方策も有限です. そのため,方策を改善し続けると,いつかはそれ以上改善しない方策にたどり着き,その方策の価値関数\(v^*\)に対して
が成り立つことがわかります.また,行動価値関数に関しても,
が成り立ちます.式(3.7),(3.8)は最適ベルマン方程式と呼ばれます. Definition 3.1から,最適価値関数も最適ベルマン方程式を満たします.
また,これら方程式を満たす価値関数に対して,
とした方策の価値関数は\(v^*\)になります.
3.2.3. ベルマン最適作用素#
前節で最適価値関数がベルマン最適方程式を満たすことを示しました. 本節では前章と同様にベルマン最適方程式をもとにした, ベルマン最適作用素(Bellman optimality operator) を導入します.
ベルマン最適作用素は,ある関数\(v : \mathcal{S} \rightarrow \mathbb{R}\)に対する写像\(B_*: \mathbb{R}^{|\mathcal{S}|} \rightarrow \mathbb{R}^{|\mathcal{S}|}\)であり,
と定義されます.
このベルマン最適作用素を用いて,式(3.7)のベルマン最適方程式を以下のように書き表せます.
このベルマン作用素に対して以下の命題が成り立ちます.
Proposition 3.3
ベルマン最適作用素\(B_*\)は,
を満たす唯一の不動点\(v^*\)を持つ. また,任意の有界関数\(v_0:\mathcal{S} \rightarrow \mathbb{R}\) に対して\(B_*\)を繰り返し適用すると漸近的に不動点に等しくなる.
Proof. \(B_\pi\)と同様,\(B_*\)が最大ノルムに対して縮小写像であることを示すことを示すことにより, バナッハの不動点定理より, この命題が示されます. 詳しくは追記します.
この命題や,今までの議論をまとめると
Proposition 3.2により任意の方策を改善できる
方策が有限であることより,方策の改善を繰り返すとこれ以上改善できない方策に行き着く
これ以上改善できない方策の価値関数はベルマン最適方程式を満たす
Proposition 3.3よりベルマン最適方程式の解は一意に定まる
ことにより,
最適価値関数\(V^*\)はベルマン方程式の唯一解となる
\(\pi^*(a|s) = \delta_{a,\mu^*(s)},\ \ \text{where }\mu^*(s) = \argmax_{a} Q^*(s,a)\)は最適方策となる
ことがわかります.
3.3. 動的計画法#
動的計画法(Dynamic Programing; DP) とは,対象とするマルコフ過程の完全な情報を用いて最適方策を求める手法を指します.
本章では前章をもとに動的計画法の一種である2つの手法,
価値反復(Value Iteration)
方策反復(Policy Iteration)
を紹介します.
3.3.1. 価値反復#
この手法の基本的な方針は,
というものです. まず最初のベルマン最適方程式の求解に関して,ベルマン方程式を解く手法と同様,直接解くか,任意の関数に\(B_*\)を繰り返し適用するかの2通りの手法が考えられます. しかし,ベルマン最適作用素は単純な線形変換ではなく\(\max_{a\in\mathcal{A}}\cdots\)と,最大値をとる操作があるため,方程式は直接解けません. なので\(B_*\)を繰り返し適用する方針で解を求めていきます.
それでは,価値反復をFrozenLakeに実装して見ましょう.
まずは,ベルマン最適作用素を関数として実装します.
def bellman_optimality_operator(v):
"""ベルマン最適作用素
Args:
v : 価値関数
Returns:
B*(v)
"""
q = np.zeros((state_size, action_size)) # 行動価値関数
for s in range(state_size):
for a in range(action_size):
q[s, a] = r(s, a) + GAMMA * np.sum(
[p(sp, s, a) * v[sp] for sp in range(state_size)] # spは次状態s'を表す
) # 行動価値関数を計算
return q.max(axis=1) # 行動価値の最大値が
このベルマン作用素を任意の\(v\)(ここでは0で初期化)に繰り返し適用すると,最適価値関数が求まります.
v = np.zeros((state_size,))
for _ in range(1000):
v = bellman_optimality_operator(v)
print(f"v =\n{v}")
v =
[0.54202593 0.49880319 0.47069569 0.4568517 0.55845096 0.
0.35834807 0. 0.59179874 0.64307982 0.61520756 0.
0. 0.74172044 0.86283743 0. ]
また,最適価値関数から,行動価値関数を作ることによって,最適方策(ここではmu)を導けます.
q = np.zeros((state_size, action_size))
for s in range(state_size):
for a in range(action_size):
q[s, a] = r(s, a) + GAMMA * np.sum(
[p(sp, s, a) * v[sp] for sp in range(state_size)]
)
mu = q.argmax(axis=1)
print(f"q =\n{q}")
print(f"mu =\n{mu}")
q =
[[0.54202593 0.52776243 0.52776243 0.52234217]
[0.34347361 0.33419814 0.31993463 0.49880319]
[0.43818949 0.43362098 0.4243455 0.47069569]
...
[0.45698409 0.5295041 0.74172044 0.49695269]
[0.73252259 0.86283743 0.82108818 0.78111957]
[0. 0. 0. 0. ]]
mu =
[0 3 3 3 0 0 0 0 3 1 0 0 0 2 1 0]
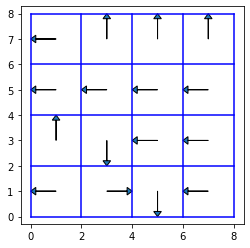
得られた方策は以下のようになります.
def plot_policy(mu):
fig, ax = plt.subplots(figsize=(4, 4))
ax.set_xlim(-1, 9)
ax.set_ylim(-1, 9)
for i in range(5):
ax.plot([i * 2, i * 2], [0, 8], color="b")
ax.plot([0, 8], [i * 2, i * 2], color="b")
dx = [-1, 0, 1, 0]
dy = [0, -1, 0, 1]
for i in range(4):
for j in range(4):
n = i * 4 + j
x = 1 + j * 2
y = 7 - i * 2
a = mu[n]
ax.arrow(
x,
y,
dx[a],
dy[a],
head_width=0.3,
head_length=0.2,
length_includes_head=True,
)
ax.axis("equal")
plt.show()
plot_policy(mu)
3.3.2. 方策反復#
この手法は,ベルマン最適方程式を直接解くのではなく, Proposition 3.2を用いて, 任意の決定的な初期方策を改善して最適方策に近づいていく手法です. ただし,方策を改善するためには,その方策の価値関数が必要なため,この手法は,
方策の価値関数を求める
それを用いて方策を改善する
という2つの処理を繰り返します.
先程と同様FrozenLakeに実装して見ましょう.
まずは,方策(ここでは決定的方策\(\mu\))に対してベルマン方程式を解く関数を実装します.ここでは,式(3.6)を直接解く方針で価値関数を求めます.
def solve_bellman_equation(mu):
"""ベルマン方程式を解いて価値関数を求める
Args:
mu : 決定的方策
Returns:
価値関数
"""
P = np.zeros((state_size, state_size)) # 確率行列
g = np.zeros((state_size,)) # 報酬ベクトル
# 報酬ベクトルと確率行列を求める
for s in range(state_size):
g[s] = r(s, mu[s])
for sp in range(state_size):
P[s, sp] = p(sp, s, mu[s])
A = np.eye(state_size, state_size) - GAMMA * P
b = g
# 線形方程式を解くことにより価値関数を求める.
return np.linalg.solve(A, b)
次に,求めた価値関数から,方策を改善する関数を実装します.
def improve_policy(v):
"""方策の改善
Args:
v : 価値関数
Returns:
改善された方策
"""
q = np.zeros((state_size, action_size)) # 行動価値関数
for s in range(state_size):
for a in range(action_size):
q[s, a] = r(s, a) + GAMMA * np.sum(
[p(sp, s, a) * v[sp] for sp in range(state_size)]
)
return q.argmax(axis=1) # 行動価値が最大となる行動を求める
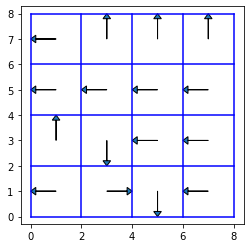
これらをもとに任意の決定的方策を方策反復により更新すると以下のようになります.
for _ in range(100):
v = solve_bellman_equation(mu)
mu = improve_policy(v)
print(f"v =\n{v}")
print(f"mu =\n{mu}")
v =
[ 5.42025932e-01 4.98803187e-01 4.70695691e-01 4.56851700e-01
5.58450960e-01 0.00000000e+00 3.58348072e-01 -3.24961973e-15
5.91798745e-01 6.43079825e-01 6.15207558e-01 0.00000000e+00
0.00000000e+00 7.41720439e-01 8.62837430e-01 0.00000000e+00]
mu =
[0 3 3 3 0 0 0 0 3 1 0 0 0 2 1 0]
得られた方策は以下のようになります.
plot_policy(mu)